
词嵌入2:Word2Vec 详解
上篇文章我们已经介绍了,用分布式表示将离散的词语转化成连续的向量,但对于 Word2Vec 没有做详细介绍,今天我们就来一起看看它。
分布式假设
如果没有词典可查或者没法请教老师,你怎么样知道两个词的相似性呢?
我们可以通过词的上下文来猜测,比如 我吃葡萄 和 我吃苹果,我们虽然无法知道葡萄和苹果都是水果,但通过这两句话,可以判断出葡萄和苹果都是食物。如果有更多的例子,比如 这葡萄真甜啊、苹果很甜、果盘里有一些葡萄、盘子中装有许多苹果等,我们大致可以猜测葡萄和苹果非常相似。因此通过分析多个上下文近似的句子,就可以得到这两个词相似性,而且句子数目越多,得到的相似性就越准确!
Word2Vec 就是基于这样一种假设——分布式假设:有相似上下文的单词的语义也是相近的。
CBOW 和 SG 模型
通过上文我们知道可以通过上下文来得到词之间的相似性,因此 Word2Vec 通常有两种形式 CBOW: Continue Bag-of-Words 和 SG: Skip-Gram,前者是用周围词预测中心词,后者是用中心词预测周围词。
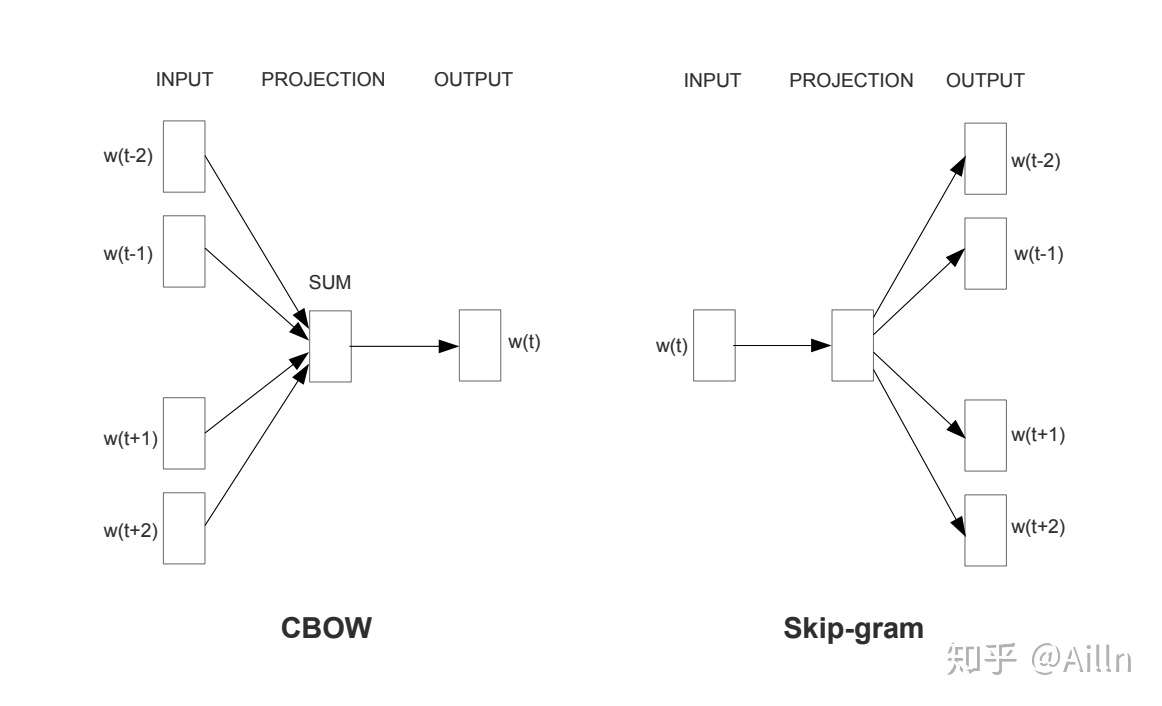
词向量实际是上述语言模型的副产物,是模型的隐藏层参数。最开始是一个随机值,随着模型不断的收敛,词向量的值不断被更新,训练良好的词向量一般为低维稠密连续的向量。(这里的低维是相对的,通常为 300)
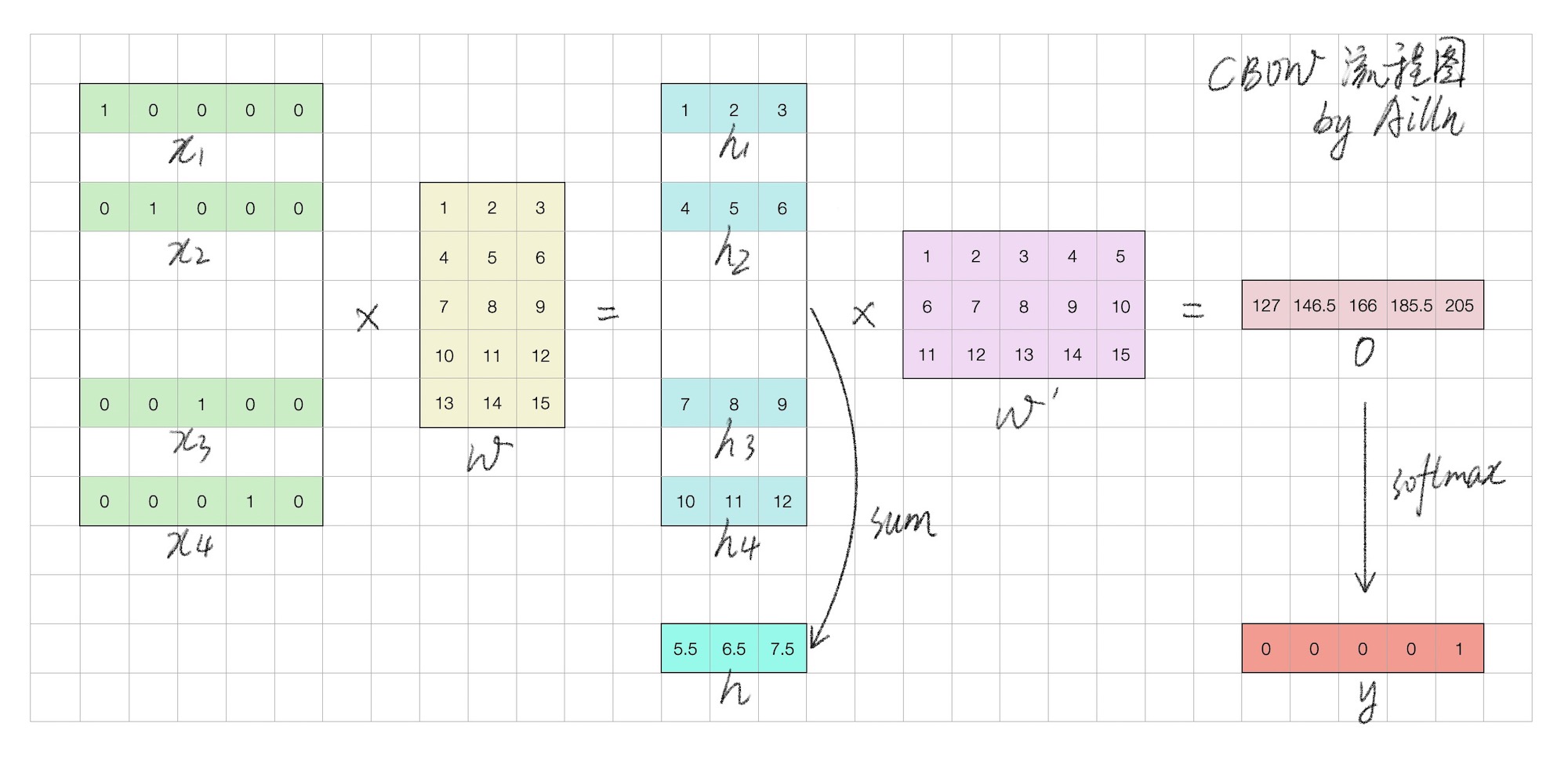
上图为 CBOW 的简化流程图,w 即是词向量矩阵,可通过索引得到每一个词的词向量。
Hierarchical Softmax
虽然我们现在可以训练词向量了,但是由于词典通常较大(假设大小为 D),所以得到的输出通常是一个 1*D 大小的向量,这样每次都要计算 D 次的 Softmax 才能得到最终输出,这样大的计算量就会使得训练速度非常慢。
Hierarchical Softmax 将输出层变成一颗二叉树,首先根据词频构建出一颗哈夫曼树,所有词典的单词都是一个叶子节点,通过非叶子节点时相当于在做一次二分类,这样就使得整体的计算量从 $O(D)$ -> $O(log_2^D)$。
Negative Sampling
在进行反向传播时,由于词典往往较大,全部更新需要 D 次(其中只有 1 个正例,有 D-1 个反例),这样计算量会很大!
解决方法就是减少更新,我们每次从 D-1 个反例中抽取 M 个,只更新 M + 1 次,就大大降低的计算量,由于是从反例中做抽样,因此被叫做 Negative Sampling。这种想法来源于噪声对比评估方法(NEC),它使得我们在没法直接完成归一化因子的计算时,就能够去估算出概率分布的参数。
派生
FastText 和 Word2Vec 中 CBOW 模型很相似,它把模型的输出由「中心词」变成了「文本标签」,其次是在于改变了输入数据,它使用了更小粒度的 subword 表示,比如当 orange 取 4-gram 时为 <ora oran rang ange nge>。这样做可以保留单词内部的形态特征,比如 orange 和 oranges 的 subword 表示几乎就是一致的。
GloVe 是一个通过词频计数来生成词向量的方法,全称为 Global Vectors for Word Representation。该模型本质上是具有加权最小二乘目标的对数双线性模型,主要直觉是简单的观察,即单词-单词共现概率的比率具有编码某种形式的含义的潜力。训练方法也很简单,第一步先根据语料库构建一个共现矩阵,然后衡量出词向量和共现矩阵之间的近似关系,最后优化目标函数。虽然它于 Word2Vec 方法不同,但也是词向量历史上一个重要里程碑!




