
神经网络中的激活函数
1 为什么要有激活函数?
众所周知,激活函数的作用是为了增加非线性因素,但这句解释其实不是很形象,今天我们用一个简单的例子说明。
假设我们需要用一层神经网络划分出平面上的点,直接使用一层神经网络,即用 $y = kx + b$ 去切分平面。
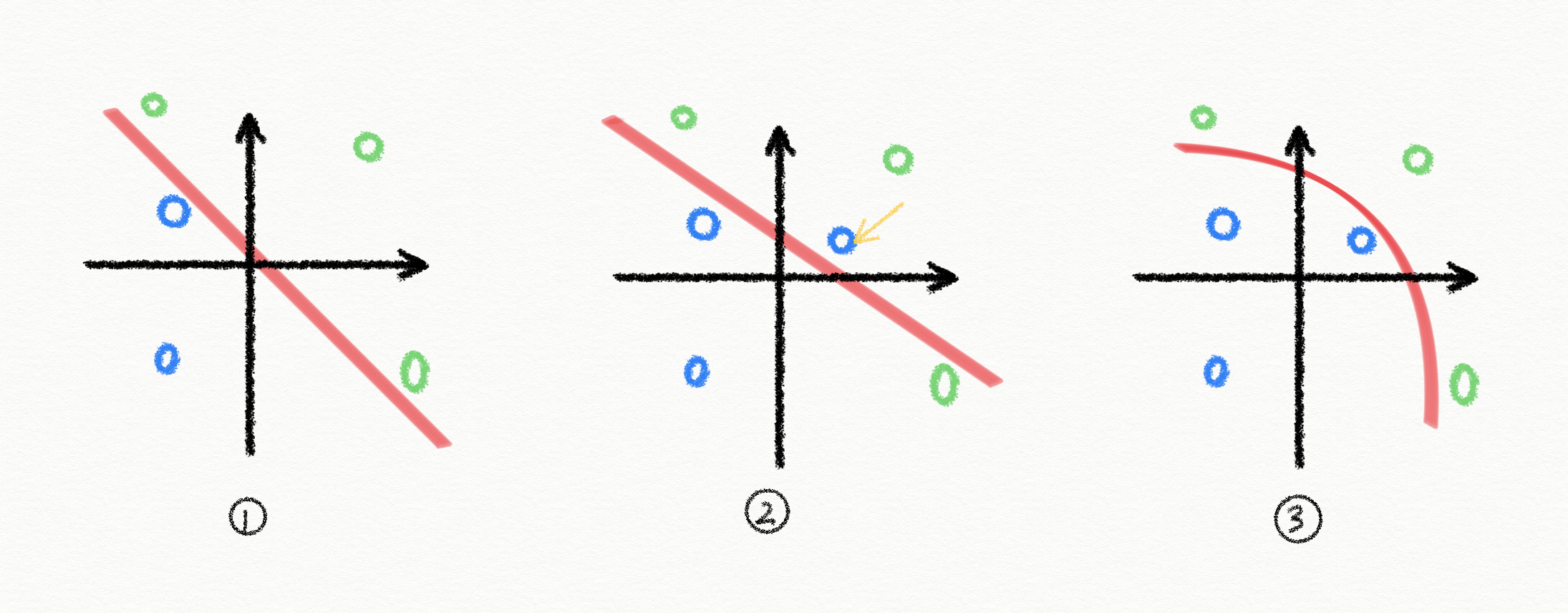
如图 1 所示,当样本点是线性可分的时候,用一条直线就能做到将蓝色的点和绿色的点分开。图 2 中又引入了一个蓝色的点(黄色箭头所示),此时用一条直线无法准确分开。
这时,我们在神经网络后面加入激活函数,比如 sigmoid 函数,原函数就变成了 $y = \frac{1}{1+e^{-(kx + b)}}$,此时原先的直线就变成了曲线,具备划分非线性可分样本的能力!(见图 3)。
真正实际应用时,假设空间往往是高维的,一刀切的情况几乎不存在。所以我们必须增加非线性因素来提高模型的拟合能力,这样才有可能找到一个更好性能的模型。
2 常见的激活函数
激活函数有很多(详情见 WIKI),但我们实际常见用到的并不多,下面四个是在深度学习框架中一定会包含的,我们一起来看看。
2.1 Sigmoid
这应该是大多数人遇到的第一个激活函数,它具有将输入映射到 0 到 1 的特性,可以大致认为是概率,因此是二分类问题的御用激活函数。
原函数
$$
y = \frac{1}{1+e^{-x}}
$$
导函数
$$
\begin{aligned}
y’ &= (\frac{1}{1+e^{-x}})’ \\
&= -1 \cdot \frac{1}{(1+e^{-x})^2} \cdot (1+e^{-x})’ \\
&= -1 \cdot \frac{1}{(1+e^{-x})^2} \cdot e^{-x} \cdot (-x)’ \\
&= \frac{1}{(1+e^{-x})^2} \cdot e^{-x} \\
&= \frac{1+e^{-x}-1}{(1+e^{-x})^2} \\
&= \frac{1}{1+e^{-x}} - \frac{1}{(1+e^{-x})^2}\\
&= \frac{1}{1+e^{-x}} \cdot (1 - \frac{1}{1+e^{-x}}) \\
&= y(1-y)
\end{aligned}
$$
分析
- 优点:将输出直接归一化成 0 到 1 的概率,函数可微。
- 缺点:容易梯度消失,指数函数计算慢。
2.2 Tanh
双曲正切函数(tanh)是双曲正弦函数(sinh)与双曲余弦函数(cosh)的比值。
原函数
$$
y = \frac{\sinh(x)}{\cosh(x)}
= \frac{e^x-e^{-x}}{e^x+e^{-x}}
$$
导函数
$$
\begin{aligned}
y’ &= (\frac{e^x-e^{-x}}{e^x+e^{-x}})’ \\
&= \frac{(e^x-e^{-x})’(e^x+e^{-x})-(e^x-e^{-x})(e^x+e^{-x})’}{(e^x+e^{-x})^2} \\
&= \frac{(e^x+e^{-x})(e^x+e^{-x})-(e^x-e^{-x})(e^x-e^{-x})}{(e^x+e^{-x})^2} \\
&= 1 - \frac{(e^x-e^{-x})^2}{(e^x+e^{-x})^2} \\
&= 1 - y^2
\end{aligned}
$$
分析
- 优点:关于原点对称。
- 缺点:输入过大过小时,梯度过小。
2.3 Softmax
原函数
$$
y = \frac{e^i}{\sum_j e^j}
$$
导函数
通常和交叉熵损失函数一起使用。(暂略)
分析
- 优点:Sigmoid 的多分类版本。
- 缺点:同 Sigmoid。
2.4 ReLU
原函数
$$
y = max(0, x)
$$
导函数
$$
y’ = 0 (x \le 0) \\
y’ = 1 (x > 0)
$$
分析
- 优点:计算速度快。
- 缺点:负区间梯度完全消失。
2.5 step
阶跃函数(step)是一种特殊的激活函数,一般不会使用,但是用来举例特别合适。
原函数
$$
y = 0 (x \le 0) \\
y = 1 (x > 0)
$$
导函数
$$
y’ = \infin (x = 0) \\
y’ = 0 (x \ne 0)
$$
分析
- 优点:计算速度快。
- 缺点:负区间梯度完全消失。




