
词嵌入1:从「分布表示」说起
⚠️ 注意:
- 一般情况下,我会在「中文术语」第一次出现时给出对应的「英文术语」,比如:自然语言处理
Natural Language Processing,当然我也有可能会忘记,欢迎用评论砸我!- 谷歌给出了它们准确而又全面的「机器学习术语表」,供参考。
1 引子
我打算用一个系列来讲述词嵌入Word Embedding(也称词向量),因为它是自然语言处理Natural Language Processing的基石,其重要程度犹如Inception Net之于计算机视觉Computer Version。
我并不打算上来就讲词嵌入是什么,而是希望通过描述相关知识引出为什么会出现词嵌入。
数据预处理Data Preprocessing是做大多数任务Task的第一步,在预处理中,我们会将原始数据的格式转化成计算机可以使用的数据形式,这种数据形式一般称为数据表示Data Representation。由于在转化时需要尽可能的保证原始数据中的信息不丢失,否则就会对任务的结果产生较大的影响,这就要求我们找到合适的数据表示方式。
在我们生活的世界里,常见的数据源有三种:「图像」、「语音」和「文本」,但它们在信息的表示上有很大差别。其中,语音和图像属于比较「低级」的表示方式,直接通过对比就可以做区分。而文本(或语言)是一种「高级」抽象的表示,比如「土豆」和「马铃薯」是同一种东西,它们所表达的含义是相同的。所以对于文本来说,我们需要一种「数据表示」来展示出更多的背景知识(或先验知识)。
以下是三种数据源不同的「数据表示」方式:
- 在图像中,用图片的像素构成的矩阵
matrix展平成向量vector后组成的向量序列来表示。 - 在语音中,数据表示方式是用音频频谱序列向量所构成的矩阵来表示。
- 在文本中,我们希望是将文本中的每一个词变成一个向量,再组合起来向量序列。
你似乎感觉到了,上文中的由文本得到的「向量序列」似乎和本文的主题「词嵌入」有某种关系。
没错,词嵌入的目的就是为了解决「数据表示」无法包含更多先验知识问题。
这里插入一点题外话,是我先前看到过的一个说法:
@王威廉:Steve Renals 算了一下 icassp 录取文章题目中包含 deep learning 的数量,发现有 44 篇,而 naacl 则有 0 篇。有一种说法是,语言(词、句子、篇章等)属于人类认知过程中产生的高层认知抽象实体,而语音和图像属于较为底层的原始输入信号,所以后两者更适合做 deep learning 来学习特征。2013 年 3 月 4 日 14:46
2 下定义
我们先来看下词嵌入Word Embedding中的嵌入Embedding是什么,这对后面的概念理解会有很大的帮助。
嵌入Embedding在数学上表示一个映射maping(即把一个数从一个范围变换到另一个范围),也就是一个函数f: X -> Y。
该函数有两个特性:
- 单射函数:每个 Y 只有唯一的 X 对应,反之亦然。
- 结构保存:在 X 所属的空间上 X1 < X2,那么映射后在 Y 所属空间上同理 Y1 < Y2。
那么 Word Embedding 和 Embedding 具有相同的性质,大致可以这样定义:
词嵌入 是把 X 所属空间的词映射为到 Y 空间的多维向量,那么该多维向量相当于嵌入到 Y 所属空间中。
通俗一点说:Word Embedding 就是找到一个映射或者函数,生成在一个新的空间上的表示,该表示被称为「单词表示」Word Representation。
3 单词表示
单词表示通常会根据数据的稀疏程度分为「稀疏表示」和「稠密表示」两种。
- 稀疏表示:独热表示
One-Hot Representation - 稠密表示:分布表示
Distributed Representation
这两种表示很好理解,稀疏就是单位空间中所包含的向量较少,而稠密就是单位空间中所包含的向量较多,具体来看下面两个例子。
3.1 独热表示
所谓独热One-Hot其实是每一个单词用一位来表示,举个例子:
有这样一句俗语叫:「三个臭皮匠,顶个诸葛亮」
分词后得到:[三, 个, 臭皮匠, 顶, 个, 诸葛亮]
去重后得到所有单词:[三, 个, 臭皮匠, 顶, 诸葛亮]
| Word | One-Hot Representation |
|---|---|
| 三 | [1, 0, 0, 0, 0] |
| 个 | [0, 1, 0, 0, 0] |
| 臭皮匠 | [0, 0, 1, 0, 0] |
| 顶 | [0, 0, 0, 1, 0] |
| 诸葛亮 | [0, 0, 0, 0, 1] |
那么上面这句话用 One-Hot 来表示,即:
1 | [ [1, 0, 0, 0, 0] |
独热表示(也称独热编码)非常简洁,它的每个单词都是一个纬度,彼此独立。再配合上最大熵ME、支持向量机SVM、条件随机场CRF等算法已经很好地完成了自然语言处理领域的各种主流任务。
但它也有很多缺点:
- 因为单词数量很多,所以导致纬度过高,通常达到了几万到几十万,高度稀疏。
- 它无法表示不同词之间的语义关系,比如:
- 语义:girl 和 woman 虽然用在不同年龄上,但指的都是女性。
- 复数:word 和 words 仅仅是复数和单数的差别。
- 时态:buy 和 bought 表达的都是「买」,但发生的时间不同。
3.2 分布表示
传统的独热表示仅仅将词符号化,不包含任何语义信息。那么如何将语义融入到词表示中呢?
分布表示Distributed Representation可以很好的解决这个问题,它将所有单词映射到一个低纬度的空间中。
如下图所示,我们通过数据降纬得到单词向量在笛卡尔坐标系内的表示。
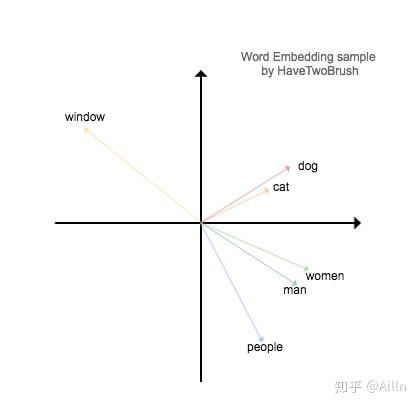
1 | window = [-5.1, 3.2, -8.8, 2.7, ...] |
它的优点有:
- 纬度低,通常只有几十到几百维;
- 词向量的方向编码来语义;
- 通过计算两个词向量之间的 cos 距离可以衡量词之间的相似度。
举几个实际应用中的例子:
- 找相关词:比如输入「马云」,计算得到最近的几个相关词「淘宝」、「马化腾」、「阿里巴巴」等;
- 迁移学习:作为 NLP 任务的 Embedding 的初始权重,可以有效提高模型的精度;
- 判断句子之间的相似度:
- v(中国) + v(首都) ≈ v(北京) => v(我/在/中国/首都) ≈ v(我/在/北京)
- v(母猫) - v(公猫) ≈ v(母狗) - v(公狗) => v(母猫/失去/了/她/的/伴侣/公猫) ≈ v(母狗/失去/了/她/的/伴侣/公狗)
4 发展
我们先来回顾以下词嵌入的发展历史。
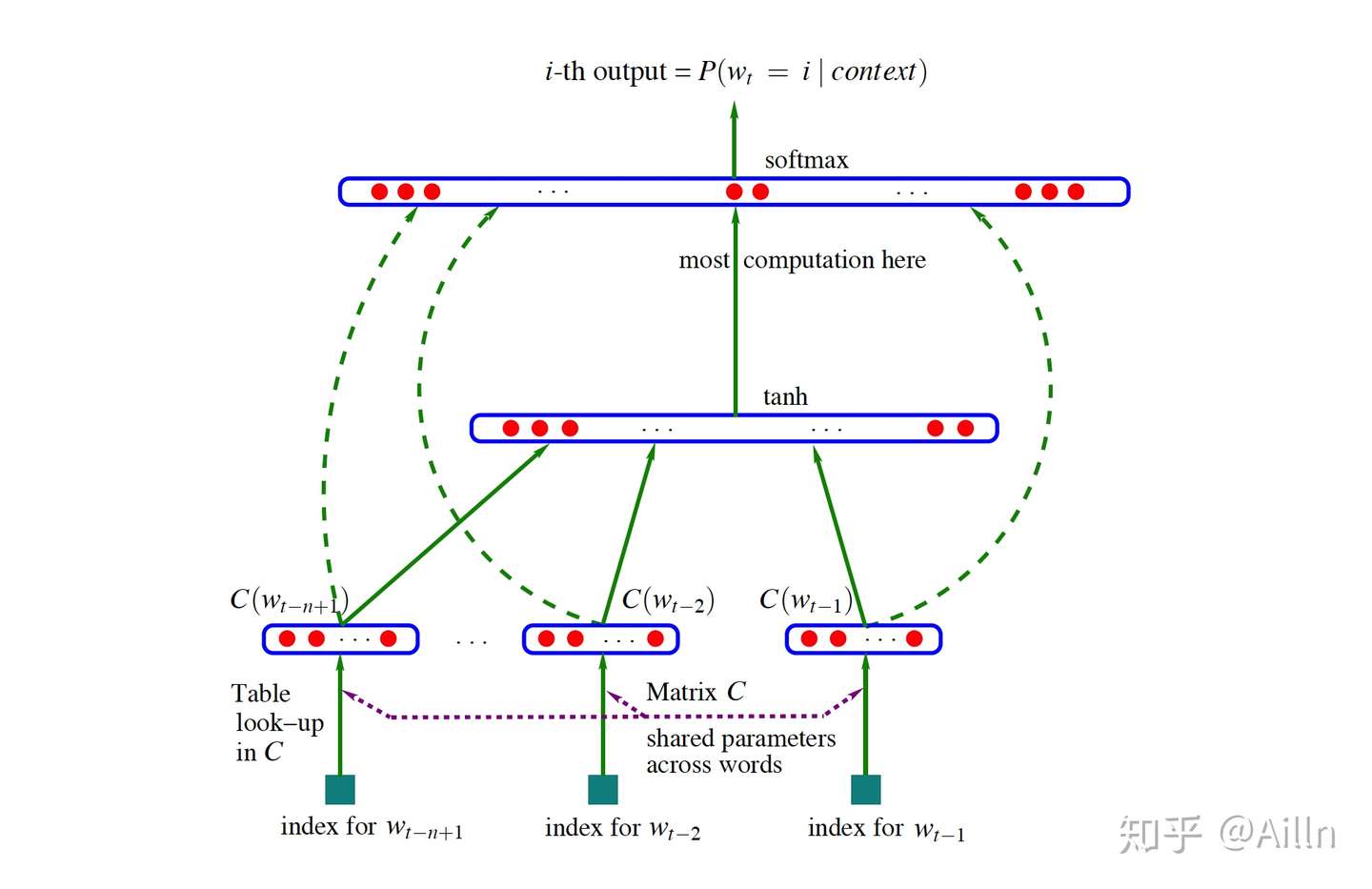
词嵌入最早可以追溯到 2003 年由 Bengio 发表的 A Neural Probabilistic Language Model一文,简称NNLM。
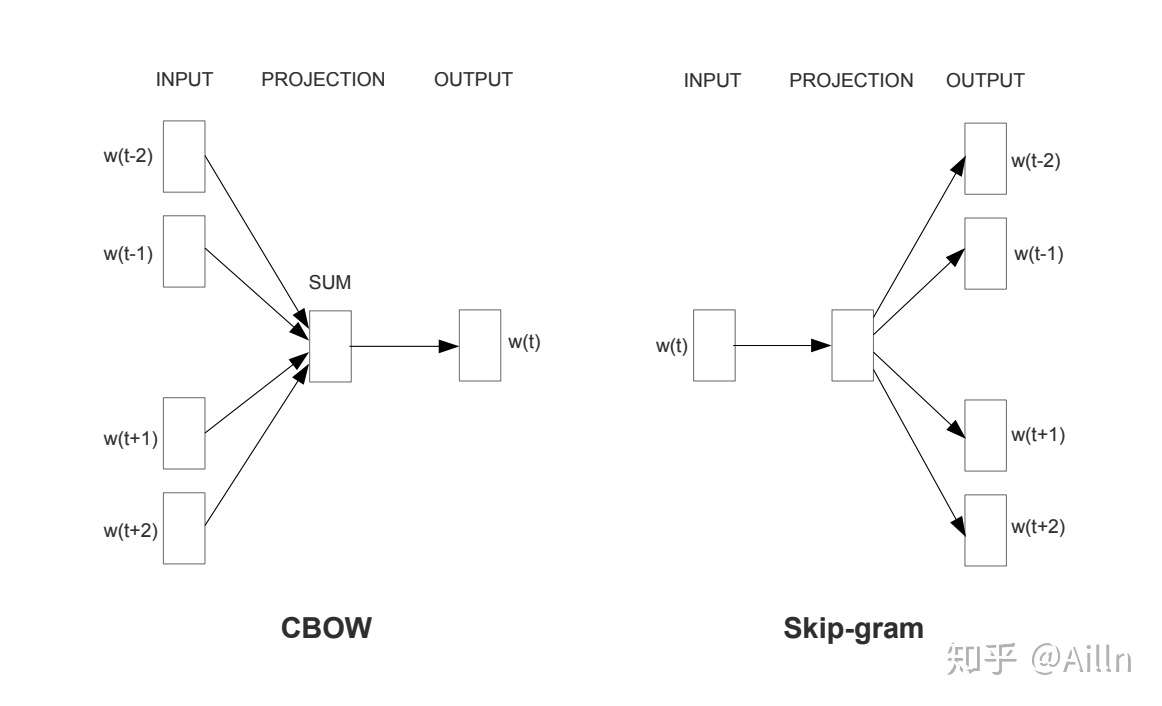
真正让词嵌入火起来是 Tomas 在 2013 年发表的Efficient Estimation of Word Representations in Vector Space,简称Word2Vector。论文不仅提出了 CBOW 和 Skip-Gram 两大模型,而且给出了简单实用的训练工具。
2014 年,Jeffrey Pennington 发表了基于「矩阵分解」的GloVe: Global Vectors for Word Representation,大大提高了训练速度。后续大家对词嵌入展开了深入的研究。
当然后续还有很多重要的相关工作,比如 FastText、ELMo、Bert等。
5 方法
词嵌入的两种主流的方法是:
- 计数法:在大型语料中统计词与相邻词的共现频率,将词映射成稠密向量。
- 预测法:使用当前词的相邻词预测当前词得到当前词的词向量。
Word2Vec 就是一种基于预测法的模型,主要有两种形式:
- CBOW
Continous Bag of Words Model:根据中心词周围的词来预测中心词。 - SG
Skip-Gram Model:根据中心词来预测中心词的周围词。
这里仅仅是做个介绍,Word2Vec 的知识有很多,后面系列中会继续讲解。
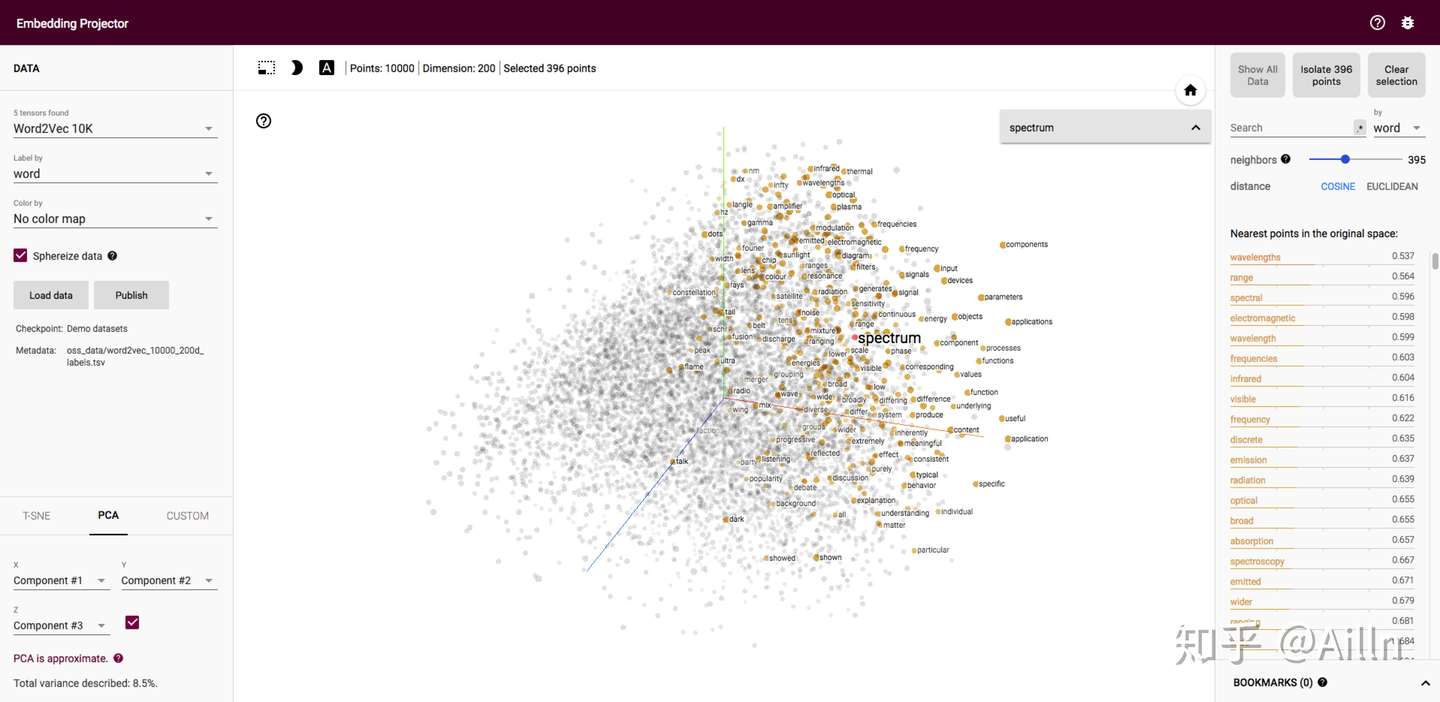
大家可以先来感受一下训练好的 Word2Vec。
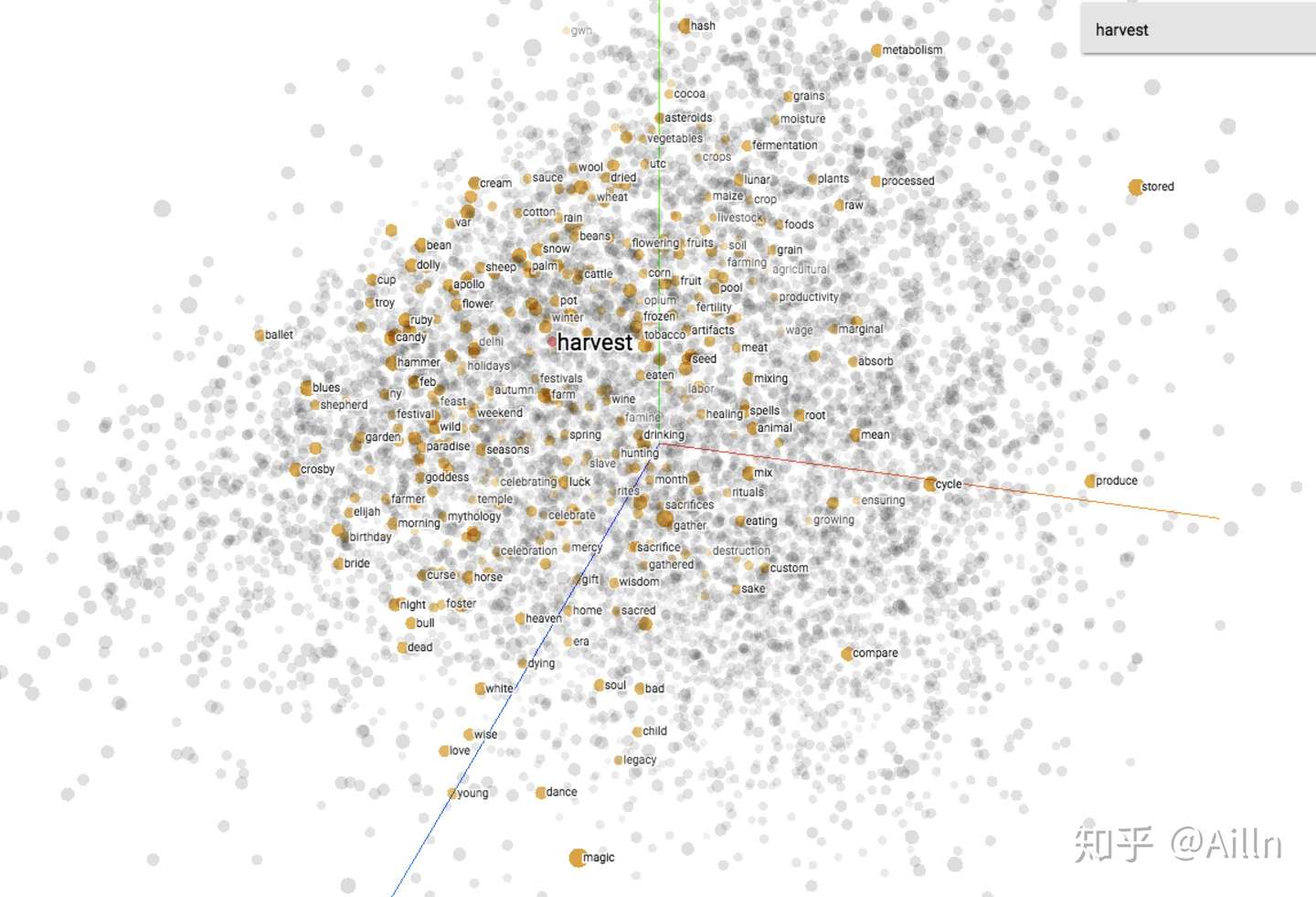
6 参考
- 有谁可以解释下 word embedding?
- YJango 的 Word Embedding–介绍
- 深度学习、自然语言处理和表征方法
- 词嵌入系列博客 Part1:基于语言建模的词嵌入模型
- 前沿综述:细数 2018 年最好的词嵌入和句嵌入技术
- Word embedding 综述与回顾(之一)—Word2Vec 模型与 PMI 分解
- A survey of cross-lingual embedding models
- A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning
- 解释 word embedding
- Word2Vec 中的数学原理详解
- TensorFlow 学习笔记 3:词向量




